
Ofte bliver vi spurgt, hvorfor man overhovedet har brug for en dedikeret dataplatform. Der findes mange gode svar på det spørgsmål, som du blandt andet kan læse om i andre af vores indlæg, HER. Der findes dog også en teknisk årsag som jeg vil forsøge at dykke ned i, med dette indlæg. For alle platforme er ikke født lige. Og det er der en rigtig god grund til, de er nemlig optimeret til forskellige brugsscenarier.
Som udenforstående kan det virke som om at data er data? Tabellerne skal bare forbindes og så kan de anvendes. Det var i hvert fald min (måske lidt naive og overfladiske) forståelse. Virkeligheden er selvfølgelig lidt mere kompliceret. Og det bunder blandt andet i forskellen mellem OLTP og OLAP dataarkitektur.
Hvad er OLTP-platforme og hvad bruges de til?
OLTP(Online Transaction Processing) dataplatforme anvendes til de systemer som en virksomhed anvender hver dag til at drive forretningen med. Ofte vil de også være omtalt som fagsystemer eller kildesystemer. De er effektive til at indsætte, opdatere og slette data hurtigt og effektivt i realtid. Det gøres med små præcise SQL statements som afvikles af de applikationer, som understøtter virksomhedens forretningsprocesser.
De er typisk kendetegnet ved at de kan bruges af mange brugere samtidigt og at de håndterer mange, men små transaktioner, de er pålidelige, de er real-time og de er robuste. Alle sammen rigtig gode ting i et IT-system, som skal afspejle et bestemt udsnit af virkeligheden.
Et andet kendetegn ved et OLTP-system er databasens design. Den typiske måde, at designe disse databaser på er med Relationel modellering. Disse tegnes typisk som vist nedenfor. Et diagram består af tre ting: entitet (tabellen), relation (forbindelsen mellem tabellerne) og attributter (variabel/kolonne i tabeller). Dette er den “almindelige” måde at opbygge databaser på.
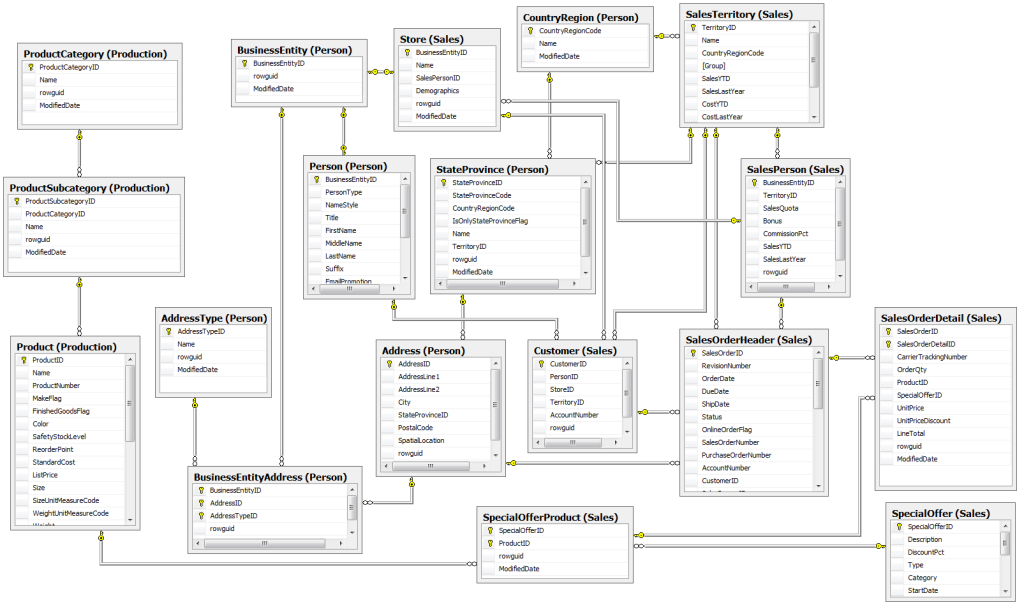
For at få den mest effektive relationelle database bruges normalisering, typisk normalisering kaldet 3NF(third normal form). Det giver et godt trade off i forhold til:
- Dataintegritet og minimering af dataredundans
- SQL kode afvikles effektivt
- Effektiv anvendelse af lagerplads
Analytiske udfordringer ved OLTP og normalisering
Når man normaliserer sin data, ofrer man dog i nogen grad muligheden for at trække data ud. Grunden til dette, er at de mange relationer mellem entiteterne, betyder at der er behov for rigtig mange “støtte”-tabeller for at lave de rigtige forbindelser. Det betyder igen, at selv simple dataudtræk hurtigt bliver kompliceret. Dermed sander datadrevne projekter til i overkomplicerede SQL-queries som skal dække mange relationer imellem mange tabeller og støttetabeller. De er både tunge for systemer at afvikle samt svære for mennesker at overskue og forstå.
Yderligere er OLTP udfordret ved at historik ikke er prioriteret. Man prioriterer istedet at overskrive data til den mest opdaterede form. Formålet med en OLTP database er som nævnt, at holde virkeligheden og et IT system ajour. Ved at bygge historik ind i en OLTP database øges kompleksiteten og datamængden nemlig betydeligt, og der mistes nogle af de oprindelige fordele ved hurtighed og robusthed.
Hvad er OLAP og hvad bruges det til?
Nogle af disse udfordringer kan opvejes ved at anlægge en dimensionel logik på en analytisk dataplatform, der supplerer de operative systemer. På den analytiske platform arbejder vi grundlæggende med at omsætte data fra de enkelte transaktioner til information i det, der kaldes OLAP(Online analytical processing). De analytiske databaser er ikke designet efter 3NF. I stedet anvendes dimensionel modellering, som består af facts og dimensioner. Når en fact forbindes med dimensioner opstår et stjerneskema, som vist nedenfor. Det er i øvrigt også typisk denne form for arkitektur, folk snakker om, når de omtaler “Kuber”.
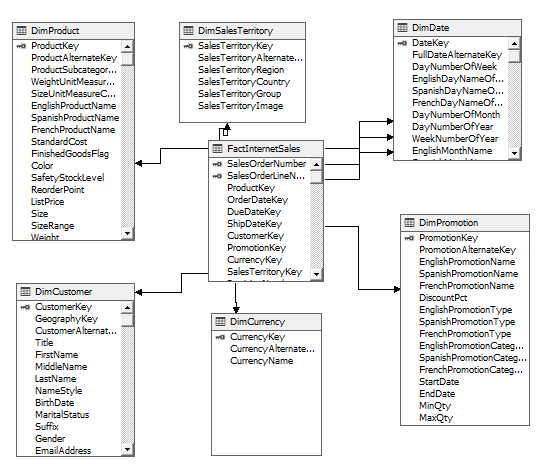
Som det fremgår, sidder facten i midten af stjerneskemaet. Facten er typisk et kvantitativt mål som har det højest mulige detaljeniveau – det er kornstørrelsen(“the grain”) i modellen. Det er altså gerne en enkelt transaktion(f.eks et salg) eller lignende. Dimensionerne indeholder kvalitativ/tekst-data som bruges til at berige fact´en med kontekst. Det er typisk dimensionerne, man vil bruge til at aggregere eller opdele factens information på forskellige måder. Dimensionel modellering er ikke-normaliseret og der tages aktivt stilling til om historik er relevant på de enkelte dimensioner. Fravælges historik omtales det som en slowly changing dimension type 1 (SCD1) tilvælges historik er der tale om SCD2 .
Fordelen ved at tilføje dimensionel logik til din forretningsdata
Fordelen ved at arbejde med dimensionel modellering er først og fremmest at det forenkler data. Med denne tilgang får du langt færre tabeller og joins og dermed et meget mere overskueligt og brugervenligt setup. Dette giver desuden også langt flere muligheder for optimering af datalagring. Yderligere vil den (gode) dimensionelle model være designet til at afspejle organisationens processer. Dermed er dataplatformen ikke bare en samling af de-normaliserede tabeller, men bevidst designede at afspejle virksomhedens forretningsprocesser og de spørgsmål som organisationen ønsker at belyse med data.
Hvad betyder det så for dig?
Som sådan betyder det ikke så meget for de fleste analytiske brugere. Men det kan være en forklaring på hvorfor mange data analytics projekter fejler. Hvorfor centrale nøgletal ikke kan produceres konsistent og med høj sikkerhed. Fordi I simpelthen mangler infrastrukturen og den grundlæggende dataplatform til at understøtte det.
Og det er en samtale, som ofte flyver under radaren for mange ledere i en forretning, som ikke er data-fokuserede. Når du hyrer konsulenter til et dataprojekt, håndterer de typisk ikke denne grundlæggende (men ofte usynlige) udfordring. De arbejder igennem på den relationelle logik, som dog ikke giver det bedste resultat på sigt.
Det er her at dataplatformen kommer ind i billedet. En dataplatform har som sin fornemmeste rolle at konvertere de relationelle tabeller fra ét (eller flere) operative systemer til én samlet dimensionel model via en række transformere (læs mere HER). Den skal altså ikke erstatte noget, men fungere som et supplement til de operative systemer, som gør dig i stand til at arbejde analytisk uden at forstyrre eller påvirke dine daglige operationer.
Vil du vide mere?
I Data Inc. er dette i kernen af den ydelse, vi leverer. Hvis du vil vide mere om fordele og ulemper ved relationel og dimensionel modellering, vil jeg anbefale at læse Lawrence Corr: “Agile data warehouse design: Collaborative dimensional modeling, from whiteboard to star schema” (Køb den HER). Det er blevet lidt af en klassisker inden for data warehouse arbejde og beskriver samtidig en pragmatisk tilgang til at designe dataplatforme – en tilgang vi i Data Inc. er meget inspireret af.
Med venlig hilsen
Mikkel




