
I vores snakke støder vi nogle gange på spørgsmål om data mesh, som en moderne dataarkitektur til håndtering af data i komplekse organisationer. Det virker på mange måder til at være det nye sort inden for moderne dataarkitektur. Derfor har jeg her forsøgt at udfolde vores tanker om hvad data mesh er, samt hvordan man som organisation kan forholde sig til det.
Det er for det første min forhåbning at afmystificere et koncept som mange måske har hørt om, men som det kan være svært helt at få fingrene omkring. For det andet vil jeg forsøge at lave den pointe, at et data mesh ikke bare er et data mesh. Der findes mange forskellige versioner af konceptet og grader af implementering.
En kort intro til Data Mesh
Først – en kort introduktion til data mesh og hovedprincpipperne bag: Konceptet blev introduceret af Zhamak Deghani (LinkedIn) i 2018. Det er altså i denne sammenhæng et relativt “ungt” koncept.
Det centrale hovedprincip i data mesh er, at arkitekturen er decentral. Det betyder at hovedparten af ansvaret for data ligger ude i decentrale data teams, som sidder tæt på der hvor data skabes og forbruges. Data mesh bryder altså med den klassiske tankegang omkring centralisering af dataejerskab, infrastruktur, kompetencer og ansvar. Dermed løser et mesh også et af de største kritikpunkter af klassisk arkitektur, nemlig at centrale data teams ofte ikke har nok viden om det data, de arbejder med, da de ikke sidder tæt på det. Det betyder, at man ofte ansætter mange datascientists for at kompensere ved forbruget, hvilket man kan undgå med brugen af mesh.
Det andet vigtige hovedprincip er, at data betragtes som et produkt. Hvert dataprodukt har en ejer som er ansvarlig for at sikre at det er relevant, kvalitetssikret og at det er tilgængeligt for de kunder (interne eller eksterne) som forbruger det.
Mesh tankegangen hviler naturligvis på cloud-teknologi, så behovet for on-prem fysisk infrastruktur er ikke eksisterende.
Der findes mange steder hvor du kan læse meget mere om de forskellige detaljer i mesh-filosofien. Du kan finde fordele og ulemper ved tilgangen og hvornår det er den rigtige tilgang for en virksomhed. Yderligere kan du også finde inspiration til de forskellige tekniske komponenter til at understøtte tilgangen (bla. standardiserede API’er, distribuerede cloud datalagring osv.). Find blandt andet infomation her, hvor Zhamak selv gennemgår de fundamentale tanker: https://www.youtube.com/watch?v=3Q_XbPmICPg
Pointen her er, at et data mesh altså ikke er en “ting”, men nærmere et koncept eller idé om hvordan man organiserer sin data og vedligeholder det. At træffe beslutning om at gå med “et mesh” er altså kun en meget overordnet, nærmest filosofisk beslutning. Det siger ikke særligt meget om hvordan man egentlig ønsker at organisere sig. Det svarer til at beslutte, at man vil have “en AI” – Det er en retning, mere end en konkret beslutning.
Glem enten/eller tankegangen
Da et data mesh primært er et abstrakt koncept, betyder det at man som firma i højere grad kan forme det til ens eget formål, historik, eksisterende infrastruktur og muligheder for at tiltrække de rette tekniske kompetencer (som forskellige grader af et Data Mesh kræver). Til det har jeg udformet tre arketypiske mesh-formater, som repræsenterer mere eller mindre “radikale” implementeringer af mesh-tankegangen. Den første er den mest rene form:
1. Det “rene” mesh
Denne tilgang er tættest på den konceptuelle idé, oprindeligt præsenteret af Zhamak. I modellen sker data-deling kun peer-to-peer eller direkte fra forretningsenhed til forretningsenhed. Kun metadata, som bruges til governance, er centraliseret og kun i “den logiske verden” (Altså ikke på en fysisk database). Data i denne model ejes, administreres og deles af hver enkelt forretningsenhed. Enhederne er fleksible og uafhængige af et centralt team til koordination eller datadistribution.
Tilgangen tilbyder fleksibilitet for de enkelte enheder og færre afhængigheder, fordi interaktionen er mange-til-mange. Derudover fremmer tilgangen genbrug af data, da tilgangen lægger op til at der skabes mange dataprodukter simultant.
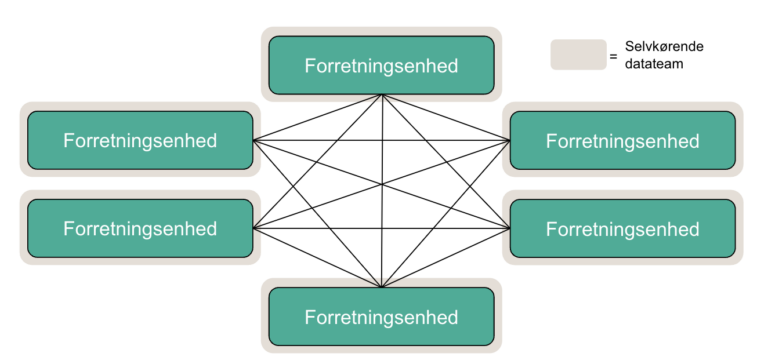
Tilgangen har dog også en række ulemper. For det første kræver det mange ressourcer, uden skaleringsfordelene ved at have en centraliseret enhed. I princippet kan en enhed have et fuldt data warehouse kørerne, som servicerer deres specifikke behov uden tanke på resten af organisationen.
Derudover stiller det også store krav til alle enhedernes individuelle evner til at opretholde sikkerhed, kvalitet, fælles standarder osv. Uden nogen central enhed til at “enforce” strømlining, er det i praksis vanskeligt. De store krav til enhederne og nødvendigheden af højt specialiserede data ingeniør-kompetencer i alle enhederne gør, at denne implementering af data mesh i praksis nærmest aldrig sker. Det er forbeholdt MEGET store organisationer, som har en meget høj data-duelighed bredt i deres enheder.
2. Distribueret ansvar med central infrastruktur
Med denne tilgang fastholdes de grundlæggende principper fra den rene tilgang, med den undtagelse, at der skydes et centralt lag ind, som varetager både samling og distribution af data. Det er typisk i et sådan scenarie, at du vil se en central data lake i anvendelse.
Derfor får du mere effektiv brug af din infrastruktur og en central enhed, der fører kontrol med datastrømmene. Der laves fortsat kun minimal dataklargøring og datarens på den centrale enhed. Det er fortsat op til enhederne at varetage denne opgave.
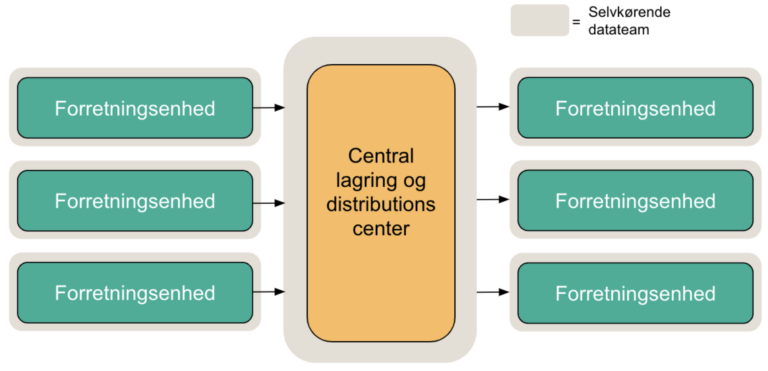
Her vil du typisk gøre brug af en ELT-tilgang kontra klassisk ETL.
Et typisk kendetegn ved klassisk data warehousing er processen kaldet ELT (Extract, Transform, Load). Det beskriver grundlæggende de tre skridt i at gøre data klar til anvendelse:
- Extract: Få data ud af kildesystemerne
- Transform: Rens og klargør data til forbrug
- Load: Placér data et sted hvor brugere kan anvende data fra
En central del af mesh-tankegangen er rækkefølge af disse tre skridt: Her hedder det Extract, Load, Transform eller ELT. Det betyder konkret at man fortsat først får data ud af kildesystemerne (selvfølgelig), men at man i stedet for at bearbejde dem, lægger dem i deres rå form til anvendelse på en platform – Typisk en datalake. Herfra er det så brugernes opgave i deres decentrale enhed at transformere data til det formål som de har med det.
Med denne tilgang fastholder man af principperne fra den rene mesh-tilgang (Data produkt og distribueret ansvar for både datainput og -output), samtidig med at man får god udnyttelse af sin infrastruktur og en central hub hvorfra adgang og kvalitet kan håndhæves.
Tilgangen mindsker derfor kravet til de uafhængige forretningsenheders datateams, både ift. vedligeholdelse af infrastruktur, men også i form af kompetencer.
3. Hybrid-forbundet Data Mesh
Ovenstående implementeringsscenarie (#2) løfter nogle opgaver fra enhederne, men stiller fortsat rigtig store krav til kompetencerne hos forretningsenhederne. De skal selv håndtere dataarkitektur, data ingeniørarbejde, foruden data science og klassiske dataanalytiske kompetencer.
Yderligere er virkeligheden i mange virksomheder, at de har et utroligt komplekst systemlandskab, med gamle systemer, som er tunge at vedligeholde og udtrække data fra. At lægge den opgave ud til forretningsenhederne er i praksis ikke en farbar vej.
En muligt meshimplementering kan i det tilfælde se således ud:
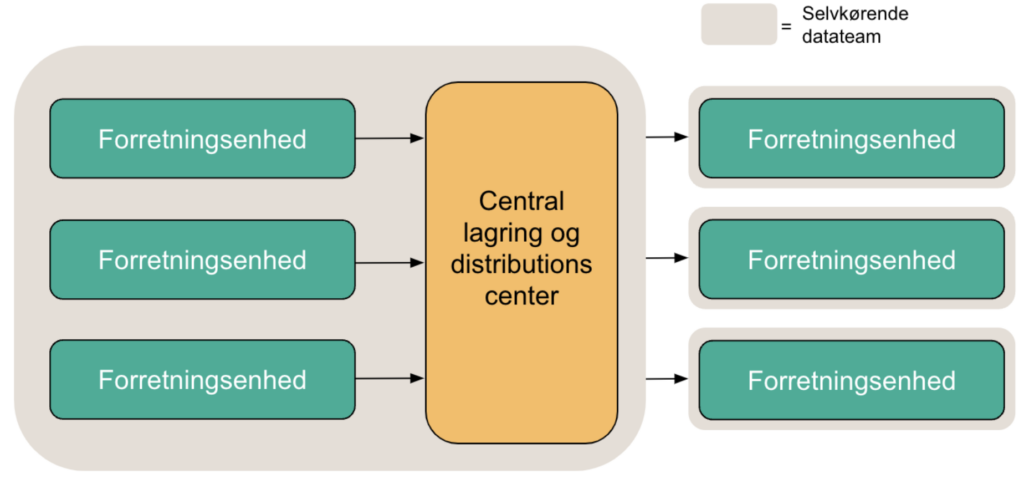
Konceptet omkring dataprodukt fastholdes stadig, men her falder endnu mere vedligehold og ansvar for dataproduktet på den centrale enhed. De tunge data-ingeniør kompetencer som er nødvendige for at vedligeholde de dataleverancer fra det komplekse systemlandskab samles centralt.
På forbrugssiden fastholdes derimod en mere strikt mesh-tankegang, hvor de enkelte enheder der anvender data, selv tager ansvar for klargøring, transformation og udstilling af den endelige data-usecase. Yderligere kan de forretningsenheder også selv tage ansvar for at stille de nye dataprodukter til rådighed til andre enheder Peer-2-Peer eller simpelthen give dem tilbage til den centrale enhed som kan distribuere dem. Her er kompetencebehovet dog mindre, da det i stedet i højere grad er datascientists og analytikere med f.eks. almindelig SQL-kompetence, som kan varetage opgaven i forretningsenheden.
Den måde som data mesh-implementering ser ud i virkeligheden
Alle de tre ovenstående modeller er arketypiske repræsentationer af hvordan mesh-filosofien kan implementeres i en data-organisation. Virkeligheden er selvfølgelig mere rodet. Nogle enheder vil selv kunne varetage deres dataopgaver til fulde, mens andre overhovedet ikke har tid, lyst eller kompetence til at levere på de krav som mesh-filosofien stiller.
I det tilfælde vil forretningsenheder have forskellige grader af autonomi, som afhænger af deres behov og kompetencer.
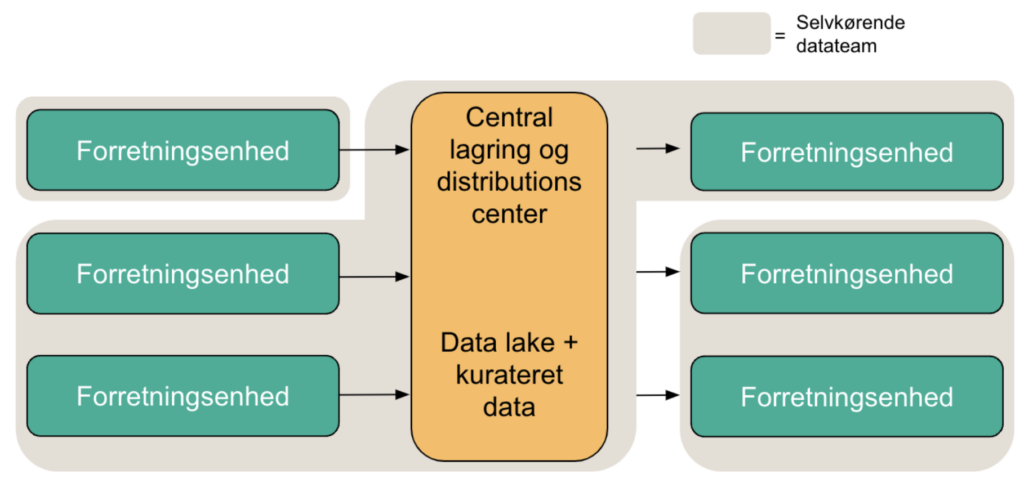
For eksempel kan en relativt nystartet produktudviklingsenhed måske i højere grad selv varetage deres forpligtelser. Både fordi at de har kompetencerne, men også fordi at deres systemlandskab er moderne og understøtter mesh-tankegangen med API’er osv. Omvendt vil der være enheder som kræver mere støtte til at navigere i deres dataprodukter.
Ligeledes på forbrugssiden kan der være enheder som ikke har kompetencer til (eller behov for) at lave avancerede analyser og dataprodukter. Det kan fx være en finansafdeling som har brug for centrale nøgletal, strømlinet på tværs af mange forretningsenheder. Altså solid kvalitetsrapportering, uden for mange dikkedarer. Her kan det centrale datateam stå for at kuratere den data på den centrale platform. Her vil mange begynde at introducere “kamre” på datalakeen, hvor der er højere og mindre grad af transformation og kuratering af data til forskellige usecases.
Endelig vil forskellige forretningsenheder “dele” datateams, igen for at overkomme kompetencebehovene, som er høje i mesh-tankegangen.
Med dette mere realistiske udgangspunkt for meshet, kan man så over tid give enhederne mere autonomi, i takt med at organisationen bliver klar. Både kulturmæssigt og kompetencemæssigt.
Og hvad betyder det så for dig?
For det første betyder det, at når du hører nogen sige, at de vil have et data mesh, eller selv overvejer om jeres organisation skal gå mesh-vejen, så er det kun den første meget overordnede tanke. Det er ikke en enten/eller.
Det gør det på måske også mindre voldsomt at vælge at gå mesh-vejen, når man forstå at mesh kommer i forskellige grader af renhed ift. de oprindelige tanker præsenteret af Zhamak. Mere pragmatiske implementeringer, hvor man låner elementer og tanker fra mesh-tankegangen, imens andre i højere grad støtter sig til den centrale enhed, kan også være rigtig gode. Langt de fleste danske virksomheder er stadig afhængige af centrale datateams.
Som leder og beslutningstager skal du have en dyb forståelse for både dit firmas aktuelle kapacitet og behov, samt hvor det er på vej hen i fremtiden. Mesh-filosofien er ikke én-størrelse-passer-alle, og som vi har gennemgået, er der flere mulig tilgange, fra fuldstændig decentralisering til mere centrale styringsmodeller.
For det andet skal der investeres i opbygning af kompetencer og kultur, hvis man ønsker at flytte mere ansvar til de enkelte forretningsenheder. Dette kan være en langsigtet investering, da det ikke kun omfatter tekniske færdigheder, men også forretningsforståelse, samarbejdsevner og en ændring i tankegangen omkring data som et aktiv.
For det tredje skal der være en forståelse for, at mens data mesh kan give større fleksibilitet og autonomi, kan det også medføre udfordringer. Eksempelvis kan det i visse situationer skabe kompleksitet i stedet for at reducere den. Især hvis forskellige enheder udvikler forskellige metoder og standarder for databehandling.
For det fjerde bør man være parat til at justere deres tilgang over tid. Som nævnt kan forskellige enheder kræve forskellige grader af støtte, og det kan være nødvendigt at revidere modelvalg i takt med at organisationen vokser, modner og tilpasser sig.
Endelig er det vigtigt at huske, at en mesh-tilgang ikke er en magisk løsning. Det er et koncept blandt mange i dataarkitektur, og det er kun så godt som de mennesker, processer og teknologier, der understøtter det. Som med enhver teknologisk implementering er det afgørende at have en klar strategi, dedikerede ressourcer og forankring i organisationens overordnede mål og vision.
Og hvad betyder det så for os?
Hos Data Inc. leverer vi dataplatforme på klassiske dyder. Det hårde arbejde med at lave data- og begrebskataloger, opnå enighed om definitioner og afklare overlap og huller i kildedata går ikke væk, af at man vælger en mesh-tankegang. Ingen teknologi eller arkitektur kan erstatte det arbejde – endnu. Og alt det arbejde laver vi netop hos Data Inc. Så kan Data Inc spille en rolle i en organisation som arbejder på et data mesh? Det korte svar er ja – Men det afhænger af hvordan du ønsker at implementere din mesh-filosofi.
Hvis man vælger den “rene” form, vil vi kunne levere platforme til én eller flere af de uafhængige forretningsenheder. Platformen skræddersyes til præcis deres behov og hvor vi kan agere det “interne” datateam som løfter forretningsenheder med rekrutteringsudfordringer. Og hvis man vælger en mere blød implementering (som vil være det mest relevante for 95% af alle danske virksomheder) er vores dataplatform fortsat oplagt til at sikre adgang til data, samtidig med at de grundlæggende behov for begrebskataloger, definitioner osv. opretholdes. Ejerskab, lineage, vedligehold og opdatering til nyeste teknologier er selvfølgelig altid en del af pakken. Kurateret og transformeret data lægges oven på efter behov, til de forretningsenheder som efterspørger det.
Jeg håber at det kunne bruges til noget 🙂
Mvh. Mikkel




