
Jeg læste for nyligt en analyse som jeg synes var rigtig interessant. Det grundlæggende spørgsmål som blev stillet var: “Hvorfor fejler så mange dataprojekter?” Det er et vanskeligt, men også utroligt centralt spørgsmål at svare på.
Præmissen for analysen er at betragte en organisations databeredskab ud fra en supply-chainperspektiv.
Data supply chain(DSC) management kan defineres som “de teknologiske trin og menneskeinvolverede processer, der understøtter strømmen af data igennem en organisationen, fra dens rå tilstand, gennem transformation og integration, hele vejen frem til analyse og forbrug” (S&P Global 451 Research)*.
I dette ligger der to grupper med fire distinkte stadier inden data overhovedet skaber værdi.
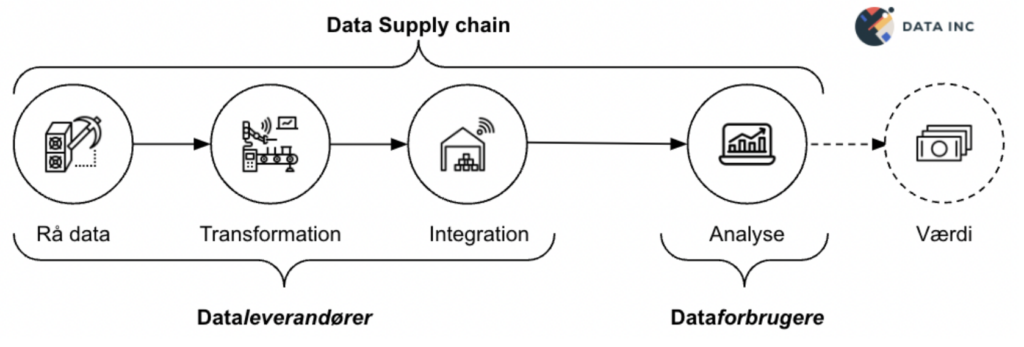
Dataleverandører
Lad os kigge på dem en ad gangen:
- Rå data: Data genereres i en række operative kildesystemer, det kan være ERP-systemet, salgssystemer, lagerstyring og diverse fagsystemer som enten er bygget inhouse eller af diverse IT-konsulenter. Det er i disse systemer at data generes og ligger som rå og ubearbejdet råstof. Det har på dette stadie potentiale, men ingen værdi i sig selv. Men det er her at den grundlæggede kvalitet i dit data bestemmes. Det første skridt i enhver data supplychain er at finde og udvinde den rå data.
- Transformation: Når data er udvundet, skal den transformeres. Allerede her kræves en grundig analyse af forretningsbehov for at sikre at data transformeres til de konkrete behov. Det er altså her at det rå data forædles til et produkt der kan anvendes i forretningen og levere den fornødne værdi. Her vil data arkitekten typisk spille en central rolle.
- Integration: I denne fase samles data fra kilderne til en samlet infrastruktur. Det pakkes, dokumenteres og gøres klar til at blive overleveret til forbrugeren.
Disse tre faser kendes for data ingeniører også under en samlet betegnelse: ETL – Extract, Transform, Load. Du kan læse mere om ETL (og ELT) her:
Ud fra et supply chain-perspektiv er disse faser uden for virksomhedens kerneydelse, men ligger som en kæde af underleverandører som sørger for at virksomheden kan levere dens ydelse eller produkt – På linje med at indkøbe andre bearbejdede eller ubearbejdede materialer til produktion. De er altså leverandører.
Dataleverandører er ansvarlig for de første tre faser. De udvinder den rå data, transformerer, integrerer og leverer den – til forbrug. Det er typisk dataingeniører, dataarkitekter, governance teams osv. som kan betragtes som leverandører.
Dataforbrugerer
I den endelige fase forbruges data. Det er altså i denne fase af organisationen “modtager” data fra deres dataleverandør og omsætter det til værdi. Det kan være til finansiel rapportering, løbende analyser, datadreven produktudvikling, AI-applikationer eller andre måder hvorpå virksomheder kan skabe værdi med data. Her er vi altså meget tættere på forretningens kerneydelse.
Dataforbrugerne anvender altså data til at skabe forretningsmæssig værdi. Det er typiske analytikere, data scientists og BI-folk eller lignende.
Dataforbrugeren overleverer indsigter til beslutningstagere eller produktteams, som altså er den endelige aftager af den rå data. Disse er altså ikke dataforbrugere i dette perspektiv, men nærmere indsigtsforbrugere.
Hvor hopper kæden af?
Hvorfor er denne inddeling interessant for at forstå hvorfor dataprojekter fejler?
Fordi at, imens at begge grupper er en del af datasupply-chainen, er dataforbrugerne historisk blevet prioriteret til fordel for dataleverandørerne. Der kan være flere grunde til det, men det handler formentligt om, at flere organisationer har ønsket at blive “datadrevet”. Og så er det oplagt at starte med det mest synlige: Dem der leverer viden til ledelsen, dem der udvikler de nye produkter, dem der leverer din konkurrencefordel. Dataforbruget kendes og forståes af ledelsen, da det er tæt på deres egen verden og forretning. Det virker – på overfladen – som det vigtigste, da det jo er kerneydelse.
Men problemet er, at dataforbrugerne ikke kan levere værdi uden et godt råmateriale fra leverandørerne. 63 procent af alle dataforbrugere rapporterer at langsom, outdated eller dårlig data er den primære barriere i deres arbejde*. Det er altså et problem upstream = længere tilbage i leveringskæden: Hos leverandørerne.
Opgaven er nu, at finde ud af hvor i leverandørkæden, at kæden hopper af. Er det I integrationen, er det i transformationen eller er det helt tilbage til den rå data i kildesystemerne?
Ny jobtitel: Data supply chain(DSC) manager
Opgaven med at finde ud af hvor kæden hopper af i en værdikæde, vil normalt varetages af en supply chain manager. I dette tilfælde Data Supply Chain manageren.
Men hvad er så problemet hos dataleverandørerne?
Leverandørerne rapporterer til gengæld manglende personale og teknisk know-how som den primære barriere for at levere værdifuld data downstream*.
Der er altså behov for at undersøge nye måde at gøre livet for dine dataleverandører nemmere. Er det nye tekniske løsninger, outsourcing eller noget helt tredje? Måske er der behov for en ny stillingsbetegnelse: Data-supply chain manageren?
Der er mange nye spørgsmål denne nye DSC-manager kan tage fat på. Han bør starte med at spørge virksomhedens analytikere (DSC-managerens “kunder”), hvor stor en del af deres tid, der reelt går med at rense og klargøre data frem for egentlig analyse? I de fleste organisationer er det sandsynligvis et sted mellem 60 – 80 procent af deres tid.
Det viser blot hvor ugunstigt forholdet mellem de to grupper er blevet, når dataforbrugerne bruger det meste af deres tid i rollen som dataleverandører. Måske er det på tide at have fokus på hele jeres data supply chain – Er det jeres råmateriale der ikke er godt nok? Er der jeres dataforædling? Eller er det leveringen til forbrugeren der mangler?
Med venlig hilsen
Mikkel Skjoldager
Head of Sales
*Fakta og inspiration er hentet her: www.immuta.com/resources/dataops-dilemma-survey-reveals-gap-in-the-data-supply-chain/




