
Der florerer mange koncepter og begreber, når man snakker om data engineering. Det er en jungle at navigere i. Hvad er forskellen på en data hub og et data mart? Hvad er det, der gør en data lake særlig?
Hos Data Incorporated arbejder vi på data warehouse-teknologi til at levere vores dataplatform. Nedenfor følger en kort begrebsafklaring, som forhåbentlig kan bidrage til en øget forståelse af, hvad en dataplatform i det hele taget er.
Jeg håber at oversigten er behjælpelig. Jeg ved i hvert fald at den var behjælpelig for mig, da jeg først gik i gang med at arbejde med dataplatforme.
Første billede viser de grundlæggende komponenter som indgår i en dataplatform, fra inputtet frem til at det “leveres” til forbrug
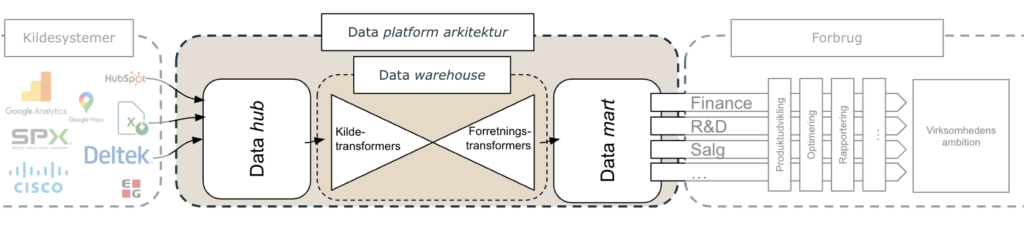
Dataplatform arkitektur: Den samlede infrastruktur der konverterer fragmenteret data fra kildesystemer til brugbar analytisk data. Nogle gange omtales den samlede arkitektur også blot som “platformen”. Den består dog af flere elementer:
Datahub: Data hub’ens funktion er at trække data fra relevante kildesystemer, samle det, og gøre det tilgængeligt for platformen. Derudover sørger Data hubben for at ‘beskytte’ kildesystemerne imod de store belastninger som en dataplatformen kræver.
Data warehouse: Her transformeres data fra data hubben til en samlet dimensionel logik. Det gøres i to skridt: kildetransformere og forretningstransformere.
- Kildetransformere: Kildetransformere håndterer alle transformationer som strømligner logikkerne fra de forskellige kildesystemer, til en uniform logik. Her opnås blandt andet “en version af sandheden” ved at alle data samles og eventuelle overlap afklares. Herfra kan alle kildesystemernes data tale sammen.
- Forretningstransformere: Med den uniforme logik på plads, transformeres data til at levere på de forskellige behov som er defineret i forretningen. Her generes blandt andet nye variable ved at opsplittet eller kombinere datapunkter fra kildesystemerne. Systematisk navngivning af datapunkter sker ligeledes her.
Data mart: Her ligger den transformerede data, helt frigjort fra kildesystemernes struktur og navne, men i stedet med fokus på forretningsens behov. Her gemmes den løbende opdaterede data, alle ændringer i tid samt dokumentationen, i et nemt og forretningsnært format. Analytikerne tilgår data fra data martet og analyserer det for at skabe værdi, på tværs af funktioner og ønsker.
Hvordan er det nu med en data lake?
Men hvad så hvis du har meget ustruktureret data? Her er en data lake den typiske vej at gå. På det andet billede kan du se hvordan en data lake typiske vil fungere i relation til dataplatformen?.
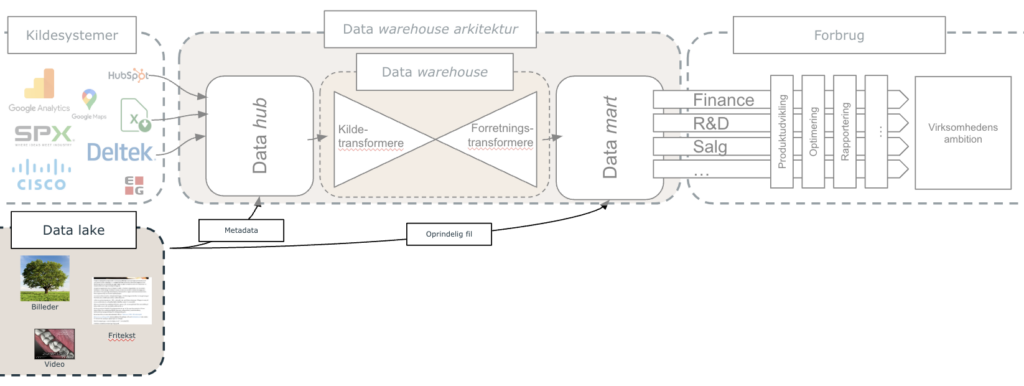
Data lake: Hvis en organisation har store mængder ustruktureret data, kan det være en fordel at have det liggende i en data lake. Her kan der ligge store mængder rå og ubearbejdet data, som kan anvendes til forskellige ad hoc analyser. Data fra data laken bør dog alligevel bindes sammen med den øvrige dataplatform arkitektur, for at give de mest værdiskabende analyser. Det gøres ved at inkludere data to steder; metadata leveres til data hubben, mens de oprindelige filer kan trækkes ind (relateres) til data i data martet efter behov.
- Metadata: Alle ustrukturede filer, har typisk en række metadata. Det kan fx være hvor og hvornår filen er genereret, hvilket kildesystem den stammer fra osv. Derudover kan der også allerede i kilden være udtrukket en række attributter fra filen, fx med brug af computer-vision algoritmer som kører i kilden. Denne data er struktureret, og kan derfor kan leveres til data huben på linje med andre kildesystemer.
- Oprindelig fil: Hvis den oprindelig fil er nødvendig, for at lave mere avancerede analyser, kan den oprindelige fil “kobles på” i data martet, med brug af metadataen.
Note: Laken kan være fysisk placeret på data hubben, i et separat “kammer”. Det gør ingen væsentlig forskel ift. hvordan data kobles eller transformeres. På den måde kan ustruktureret data også sagtens inkluderes på en selve dataplatformen.
Og hvad med alle de andre?
Med data platformen og data laken på plads er du rigtig langt. Der findes en lang række andre begreber: Data fabric, lake house osv. Fælles for dem alle, er at de bygger på de samme teknologier. For langt de fleste virksomheder vil de gennemtestede koncepter som vi har gennemgået være mere end tilstrækkelige. Faktisk vil mere komplicerede setups kun gøre det vanskeligere at vedligeholde uden nogen yderligere fordel.
Jeg håber at denne korte gennemgang kan hjælpe til at give lidt overblik og måske også afmystificere et område som kan være fremmed for mange
Med venlig hilsen
Mikkel
Head of Sales




